Free & Open Source CLI · Local-First · Rust + Python
modl
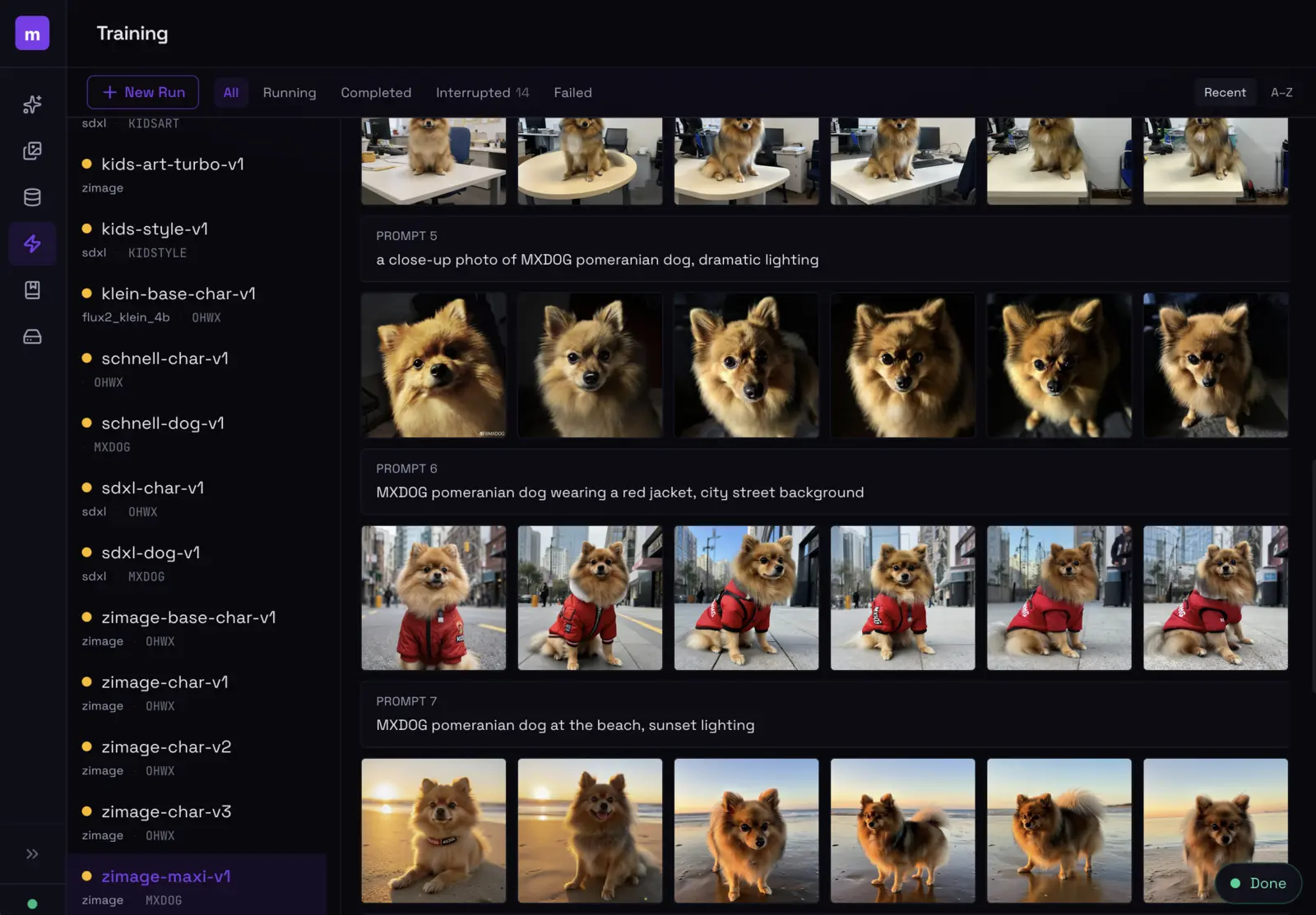
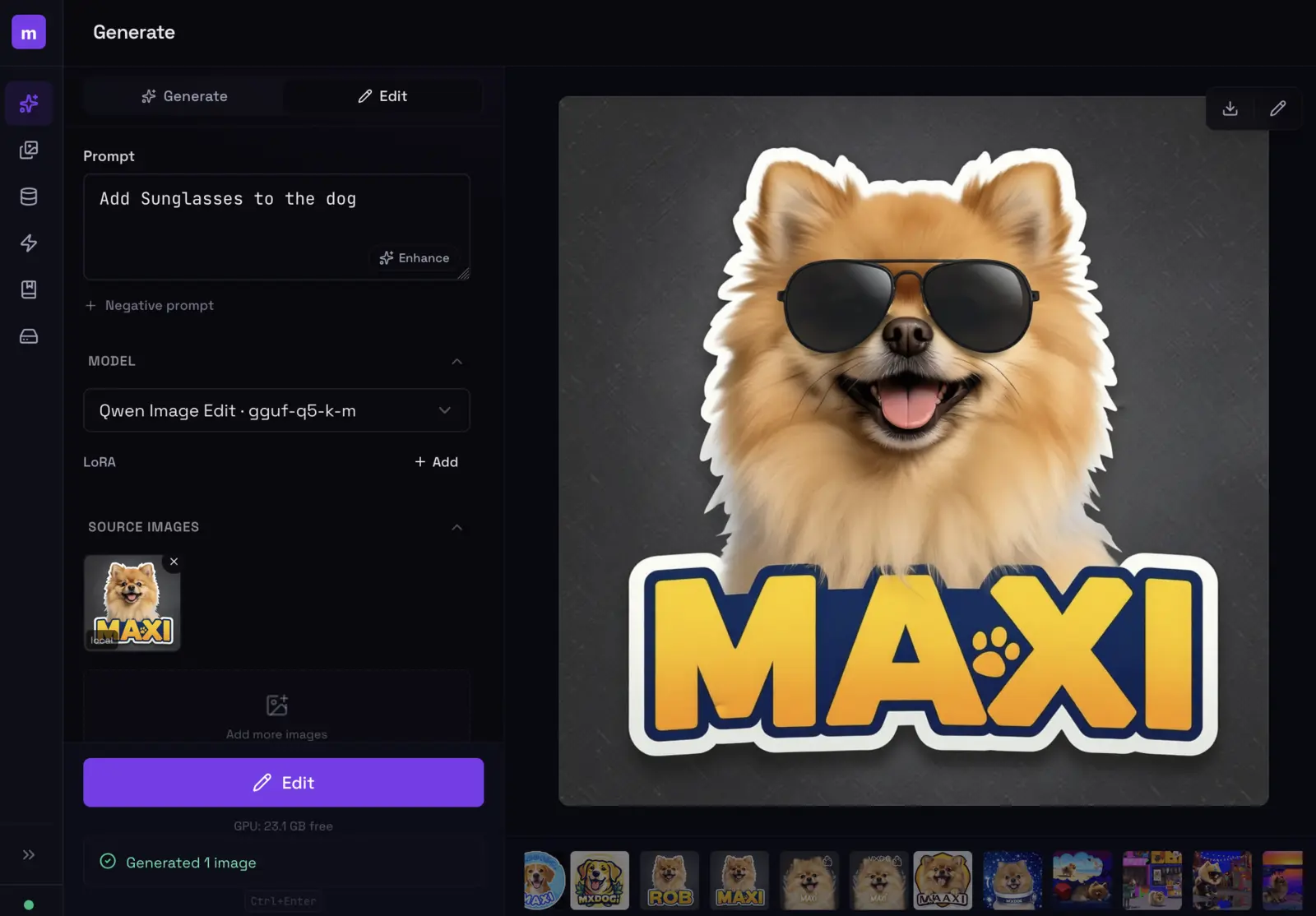
Train a LoRA from photos, generate images of yourself.
Two commands, no setup.
$ modl train --dataset ./photos --base flux-dev --name my-style
▸ Training ████████████████ 1500/1500 steps
✓ LoRA saved: my-style
$ modl generate "me on a rooftop at sunset" --lora my-style
▸ Generating ████████████████ 20/20 steps
✓ ~/.modl/outputs/2026-03-23/001.png





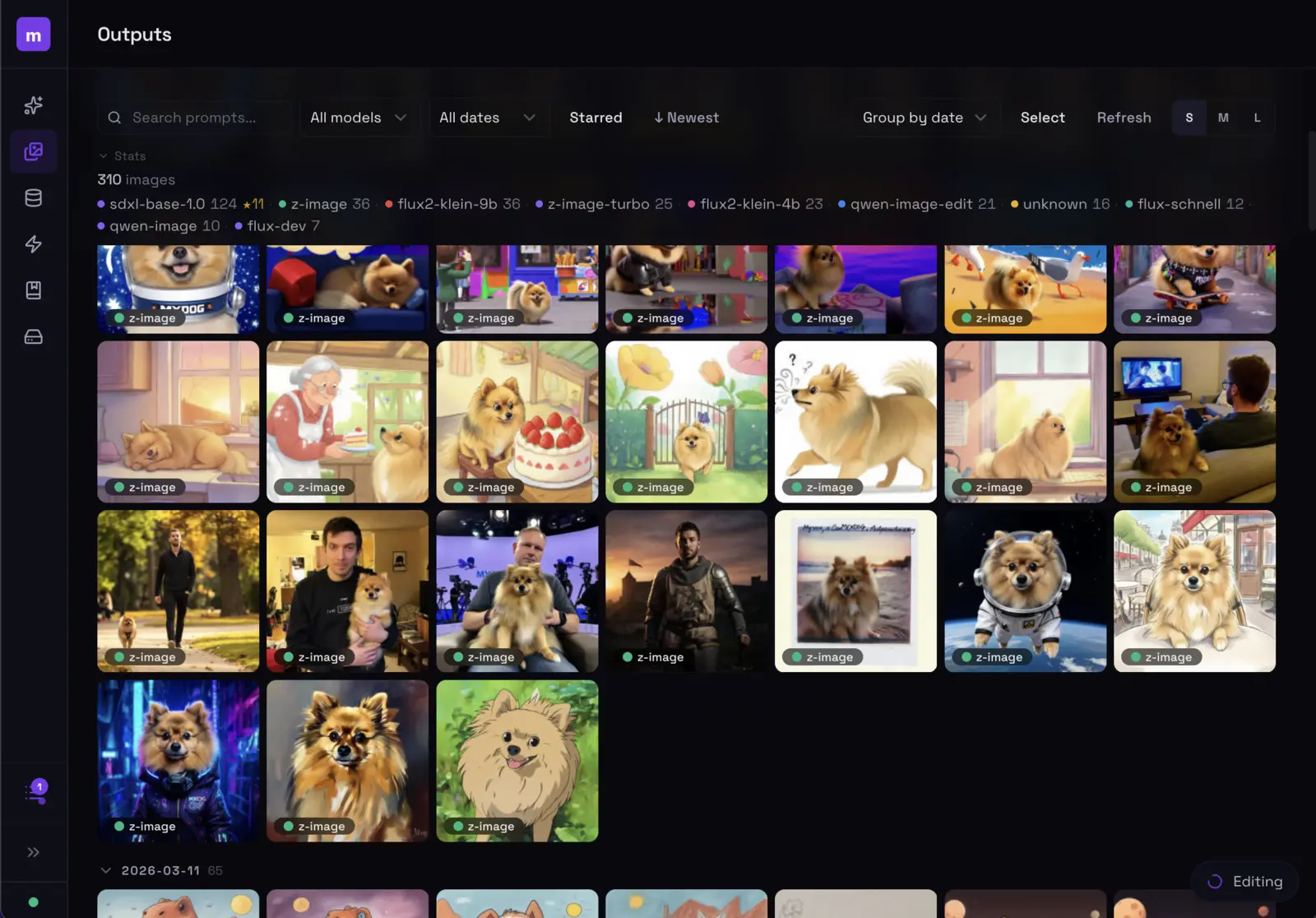
Generated with modl — products, portraits, landscapes, art, and your own trained subjects
curl -fsSL https://modl.run/install.sh | sh